Chapter 3 Molecular and Cell Biology
Since the 1980s, there has been an explosion in knowledge regarding molecular and cellular biology. These advances will transform the practice of surgery to one that is based on molecular techniques for the prevention, diagnosis, and treatment of many surgical diseases. This has been made possible by the achievements of the Human Genome Project, which is intended to reveal the complete genetic instruction of humans. The core knowledge of molecular and cellular biology has been presented in detail in several textbooks.1,2 An overview of the field is presented here, with emphasis on basic concepts and techniques.
Human Genome
Mendel first defined genes as information-containing elements that are distributed from parents to offspring. Genes contain the design that is essential for the development of each human. The field of molecular biology began in 1944, when Avery demonstrated that DNA was the hereditary material that made up genes. Translation of this genetic information into RNA and then protein leads to the expression of specific biologic characteristics or phenotypes. Major advances made in the field of molecular biology are listed in Table 3-1. In this section, the structures of genes and DNA are reviewed, as are the processes whereby genetic information is translated into biologic characteristics.
Table 3-1 Major Events in Molecular Biology
| YEAR | EVENT |
|---|---|
| 1941 | Genes are found to encode proteins. |
| 1944 | DNA is determined to carry the genetic information. |
| 1953 | DNA structure is determined. |
| 1962 | Restriction endonucleases are discovered. |
| 1966 | Genetic code is deciphered. |
| 1973 | DNA cloning technique is established. |
| 1976 | First oncogene is discovered. |
| 1977 | Human growth hormone is produced in bacteria. |
| 1978 | Human insulin gene is cloned. |
| 1981 | First transgenic animal is produced. |
| 1985 | Polymerase chain reaction is invented. |
| First tumor suppressor gene is discovered. | |
| 1990 | Human Genome Project is created. |
| 1998 | First mammal is cloned. |
Structure of Genes and DNA
DNA is composed of two antiparallel strands of unbranched polymer wrapped around each other to form a right-handed double helix (Fig. 3-1).3 Each strand is composed of four types of deoxyribonucleotides containing the bases adenine (A), cytosine (C), guanine (G), and thymine (T). The nucleotides are joined together by phosphodiester bonds that join the 5′carbon of one deoxyribose group to the 3′ carbon of the next. Whereas the sugar-phosphate backbone remains constant, the attached bases can vary to encode different genetic information. The nucleotide sequences of the opposing strands of DNA are complementary to each other, thus allowing the formation of hydrogen bonds that stabilize the double-helix structure. Complementary base pairs require that A always pairs with T and C always pairs with G.
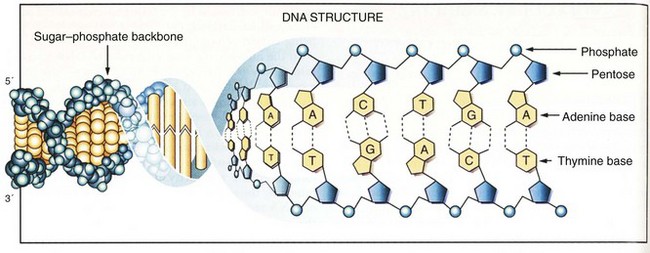
The entire human genetic information, or human genome, contains 3 × 109 nucleotide pairs. However, less than 10% of the DNA sequences are copied into messenger RNA (mRNA) molecules, which encode proteins, or structural RNA, such as transfer RNA (tRNA) or ribosomal RNA (rRNA) molecules. Each nucleotide sequence in a DNA molecule that directs the synthesis of a functional RNA molecule is called a gene (Fig. 3-2). DNA sequences that do not encode genetic information may have structural or other unknown functions. Human genes commonly contain more than 100,000 nucleotide pairs, yet most mRNA molecule–encoding proteins consist of only 1000 nucleotide pairs. Most of the extra nucleotides consist of long stretches of noncoding sequences, called introns, that interrupt the relatively short segments of coding sequences called exons. For example, the thyroglobulin gene has 300,000 nucleotide bases and 36 introns, whereas its mRNA has only 8700 nucleotide bases. The processes whereby genetic information encoded in DNA is transferred to RNA and protein molecules are discussed later.

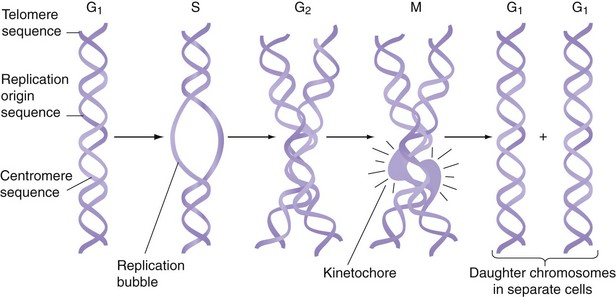
The human genome contains 24 different DNA molecules; each DNA has 108 bases and is packaged in a separate chromosome. Thus, the human genome is organized into 22 different autosomes and two different sex chromosomes. Because humans are diploid organisms, each somatic cell contains two copies of each different autosome and two sex chromosomes, for a total of 46 chromosomes. One copy of chromosomes is inherited from the mother and one is inherited from the father. Germ cells contain only 22 autosomes and one sex chromosome. Each chromosome contains three types of specialized DNA sequences that are important in the replication or segregation of chromosomes during cell division (Fig. 3-3). To replicate, each chromosome contains many short, specific DNA sequences that act as replication origins. A second sequence element, called a centromere, attaches DNA to the mitotic spindle during cell division. The third sequence element is a telomere, which contains G-rich repeats located at each end of the chromosome. During DNA replication, one strand of DNA becomes a few bases shorter at its 3′ end because of limitation in the replication machinery. If this is not remedied, DNA molecules will become progressively shorter in their telomere segments with each cell division. This problem is solved by an enzyme called telomerase, which periodically extends the telomerase sequence by several bases.
DNA Replication and Repair
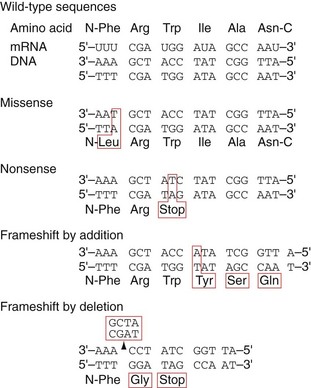
Eventually, two complete DNA double helices are formed that contain identical genetic information. The fidelity of DNA replication is of critical importance because any mistake, called a mutation, will result in wrong DNA sequences being copied to daughter cells. Mistake in a single base pair is called a point mutation, which results in a missense mutation or nonsense mutation (Fig. 3-4). In a missense mutation, a single amino acid is changed, which can cause changes in the structure of the protein, leading to altered biologic activity. In a nonsense mutation, point mutation results in the replacement of an amino acid codon with a stop codon, leading to premature termination of translation and truncation of the encoded protein. If there is an addition or deletion of a few base pairs, it is called a frameshift mutation, which leads to the introduction of unrelated amino acids or a stop codon. Some mutations are silent and will not affect the function of the organism. Several proofreading mechanisms are used to eliminate mistakes during DNA replication.
RNA and Protein Synthesis
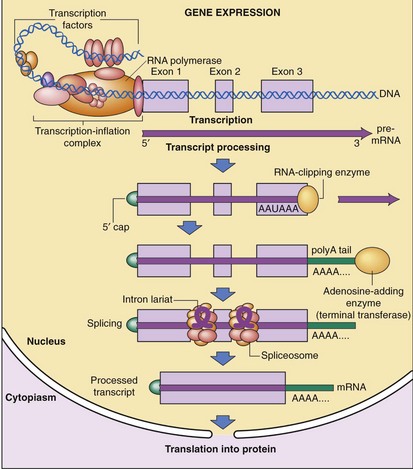
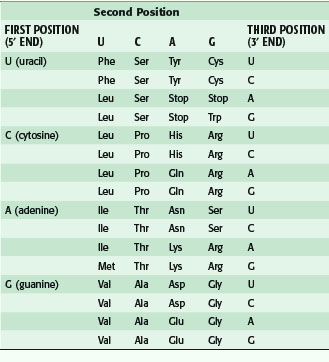
After transcription, mRNA is processed for transport out of the nucleus (Fig. 3-5). One important step is RNA splicing, which removes noncoding sequences or introns. Once in the cytoplasm, RNA directs the synthesis of a particular protein through a process called RNA translation. The sequence of nucleotides in mRNA is translated into the amino acid sequence of a protein. Each triplet of nucleotides forms a codon that specifies one amino acid. Because RNA is composed of four types of nucleotides, there are 64 possible codon triplets (4 × 4 × 4). However, only 20 amino acids are commonly found in proteins, so most amino acids are specified by several codons. The rule whereby different codons are translated into amino acids is called the genetic code (Table 3-2).
Control of Gene Expression
The human body is made up of millions of specialized cells, each performing predetermined functions. This is characteristic of all multicellular organisms. In general, different human cell types contain the same genetic material (i.e., DNA), yet they synthesize and accumulate different sets of RNA and protein molecules. This difference in gene expression determines whether a cell is a hepatocyte or a cholangiocyte. Gene expression can be controlled at six major steps in the synthetic pathway from DNA to RNA to protein.4 The first control is at the level of gene transcription, which determines when and how often a given gene is transcribed into RNA molecules. The next step is RNA processing control, which regulates how many mature mRNA molecules are produced in the nucleus. The third step is RNA transport control, which determines which mature mRNA molecules are exported into the cytoplasm where protein synthesis occurs. The fourth step involves mRNA stability control, which determines the rate of mRNA degradation. The fifth step involves translational control, which determines how often mRNA is translated by ribosomes into proteins. The final step is post-translational control, which regulates the function and fate of protein molecules.
Control of gene transcription is the best studied step of regulation for most genes. RNA synthesis begins with assembly and binding of the general transcription machinery to the promoter region of a gene (see Fig. 3-5). The promoter is located upstream of the transcription initiation site at the 5′ end of the gene and consists of a stretch of DNA sequence primarily composed of T and A nucleotides (i.e., the TATA box). The general transcription machinery is composed of several proteins, including RNA polymerase II and general transcription proteins. These general transcription factors are abundantly expressed in all cells and are required for the transcription of most mammalian genes. The rate of assembly of the general transcription machinery to the promoter determines the rate of transcription, which is regulated by gene regulatory proteins. In contrast to the small number of general transcription proteins, there are thousands of different gene regulatory proteins. Most bind to specific DNA sequences, called regulatory elements, to activate or repress transcription.
Post-translational control is another important step in the regulation of gene expression because most proteins are modified in one form or another.5 Modifications such as proteolytic cleavage, disulfide formation, glycosylation, lipidation, and biotinylation allow the protein to achieve the proper structural conformation essential for its biologic activity. The complexity of regulation is greatly increased by additional amino acid modifications that can occur at multiple sites of a protein. Examples of amino acid modification include phosphorylation, acetylation, methylation, ubiquitination, and sumoylation.
Recombinant DNA Technology
Advances in recombinant DNA technology, beginning in the 1970s, have greatly facilitated study of the human genome. It is now routine practice in molecular laboratories to excise a specific region of DNA, produce unlimited copies of it, and determine its nucleotide sequences. Furthermore, isolated genes can be altered (engineered) and transferred back into cells in culture or into the germline of an animal or plant so that the altered gene is inherited as part of the organism’s genome. The most important recombinant DNA technology includes the ability to cut DNA at specific sites by restriction nucleases, rapidly amplify DNA sequences, quickly determine the nucleotide sequences, clone a DNA fragment, and create a DNA sequence.6
Restriction Nucleases
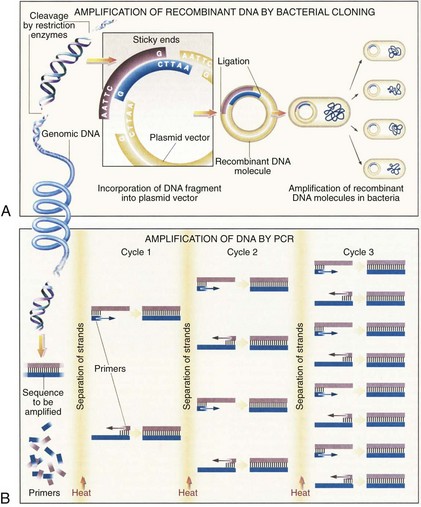
Restriction nucleases are bacterial enzymes that cut the DNA double helix at specific sequences of four to eight nucleotides. More than 400 restriction nucleases have been isolated from different species of bacteria and they recognize over 100 different specific sequences. Commonly used restriction enzymes often recognize a six–base pair palindromic sequence, such as GAATTC. Each restriction nuclease will cut a DNA molecule into a series of specific fragments, which can be joined to other DNA fragments with compatible ends (Fig. 3-6A). By using a combination of different restriction enzymes, a restriction map of each DNA can be created, thus facilitating the isolation of individual genes.
Polymerase Chain Reaction
An ingenious technique to amplify a segment of a DNA sequence in vitro rapidly was developed in 1985 by Saiki and coworkers.7 This method, called the polymerase chain reaction (PCR), can enzymatically amplify a segment of DNA a billion-fold. The principle of the PCR technique is illustrated in Figure 3-6B.
< div class='tao-gold-member'>
Stay updated, free articles. Join our Telegram channel

Full access? Get Clinical Tree


